什么是Pandas?
官网介绍:pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language.
Pandas 是一个快速、强大、灵活且易于使用的开源数据分析和处理工具,它建立在 Python 编程语言之上。
Pandas的特点
Pandas提供了丰富的功能,使得数据处理和分析更为便捷:
- 数据选择和过滤:通过行标签,列标签,位置等方式选择数据
- 数据清洗:处理缺失值和缺省值,转换数据类型等
- 数据聚合:对数据进行分组并应用聚合函数
- 数据合并和连接:合并多个DataFrame
- 时间序列处理:处理时间和日期相关的数据
Pandas是数据科学家和分析师在Python生态系统中的重要工具,让数据分析变得高效且简便。它还与其他Python库(Numpy,Matplotlib,Scikit-learn 等)紧密集成,形成了一个强大的数据处理和分析平台。
如何安装Pandas
pip install pandas
如果pip没有进行换源,并且从官网下载速度过慢,可以使用清华源进行下载
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
什么是Series?
- 在Pandas中,Series是一种一维标记数组,是Pandas提供的主要数据结构之一。
- Series可以看作是带有标签(索引 Index)的一维数组,类似于Python中的列表,但具有更加强大的功能
- Series可以包含任意类型的数据,包括整数,浮点数,字符串,Python对象等
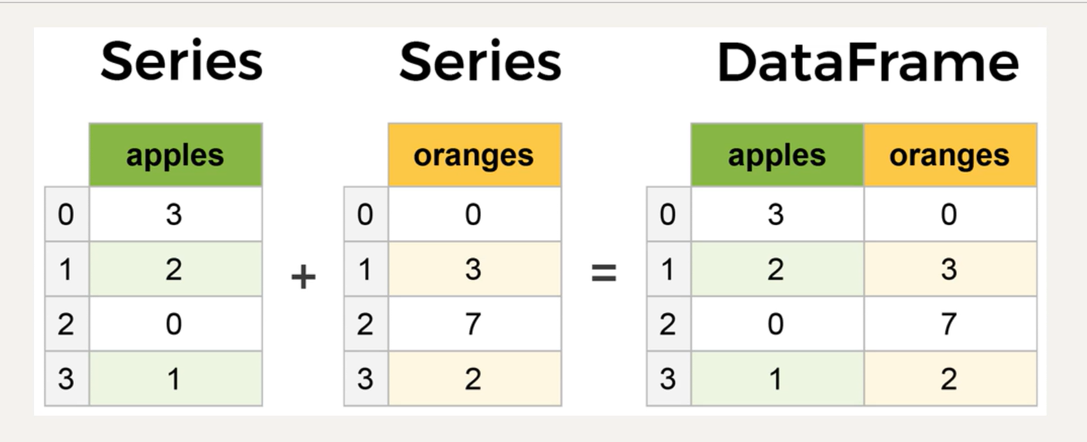
如下图所示,多个Series可以合并为一个DataFrame,DataFrame不妨看作是Excel表
代码实现
# 导入库
import numpy as np
import pandas as pd
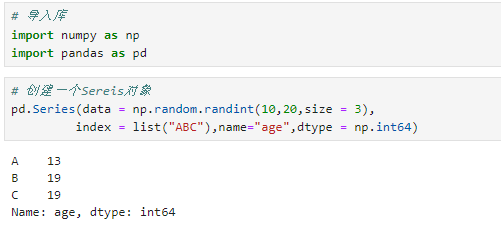
# 创建一个Sereis对象
pd.Series(data = np.random.randint(10,20,size = 3),
index = list("ABC"),name="age",dtype = np.int64)
在jupyter中的实现效果
Series如何索引?
什么是索引?
索引,也叫Index,指的是如何在Series中取到指定的值。如图所示,下面有一个Series,可以分为两列,一列是索引Index,另一列是值Value,值与其索引一一对应,因此我们需要取到Series中的某个特定值时,只需知道它的索引即可。

在Pandas中,可以使用不同类型的索引来访问和操作Series中的数据,以下是Series的主要索引方法:
位置索引
位置索引->使用整数位置索引,类似于Python中的列表索引
位置索引从
0开始,可以使用方括号[整数]或者iloc[整数],来访问该整数对应的Series中的元素代码示例
python# 导入库 import pandas as pd # 创建数据,索引,序列 data = [10, 20, 30, 40, 50] index = ['A', 'B', 'C', 'D', 'E'] series = pd.Series(data,index=index) # 访问单个元素 print(series[0]) print(series.iloc[0])在使用jupyter运行上述代码时,输出均为10,然而series却显示提示

该提示主要是指,Pandas库中的
Series对象的__getitem__方法(即用于索引和切片的方法)的行为即将改变。在当前的版本中,如果你使用整数作为索引来访问
Series对象中的元素,Pandas会将这个整数视为一个位置索引,即它会返回索引为该整数的元素。但是,在未来的版本中,整数索引将不再被视为位置索引,而是被视为标签索引。这意味着,如果你使用整数索引来访问元素,Pandas将会尝试找到具有该整数标签的元素,而不是返回位于该位置的元素。也就是说,为了代码的良好维护性,建议将整数索引修改为iloc索引
标签索引
标签索引是指使用
自定义的索引标签来访问和操作Series中的数据使用方括号[标签名]或者loc[标签名]来获取标签名对应的Series中的单个元素
代码示例
python# 导入库 import pandas as pd # 创建数据,索引,序列 data = [10, 20, 30, 40, 50] index = ['A', 'B', 'C', 'D', 'E'] series = pd.Series(data,index=index) # 访问单个元素 print(series['B']) #输出 20 print(series.loc['B']) #输出 20
Series如何切片?
什么是切片?
切片操作是编程中一种常见的数据访问技术,特别是在处理数组、列表或序列类型的数据结构时。在Python中,切片操作允许你从一个序列中提取一部分元素,创建一个新的序列
在Pandas中,可以使用切片操作从Series中提取子集数据。切片操作可以基于位置索引(整数位置)或者标签索引(自定义索引标签)进行,具体取决于在切片时使用的是iloc还是loc
位置索引
切片的范围是左闭右开的,即包含切片起始位置元素但不包含结束位置元素
代码示例
python# 导入库 import pandas as pd # 创建数据,索引,序列 data = [10, 20, 30, 40, 50] index = ['A', 'B', 'C', 'D', 'E'] series = pd.Series(data,index=index) # 使用iloc切片数据 s = series.iloc[1:4] # 展示数据 s不难发现,切片得到的
s序列有三个元素,他们的索引分别是BCD,包含了起始位置元素对应的B,但是没有包含结束位置元素对应的E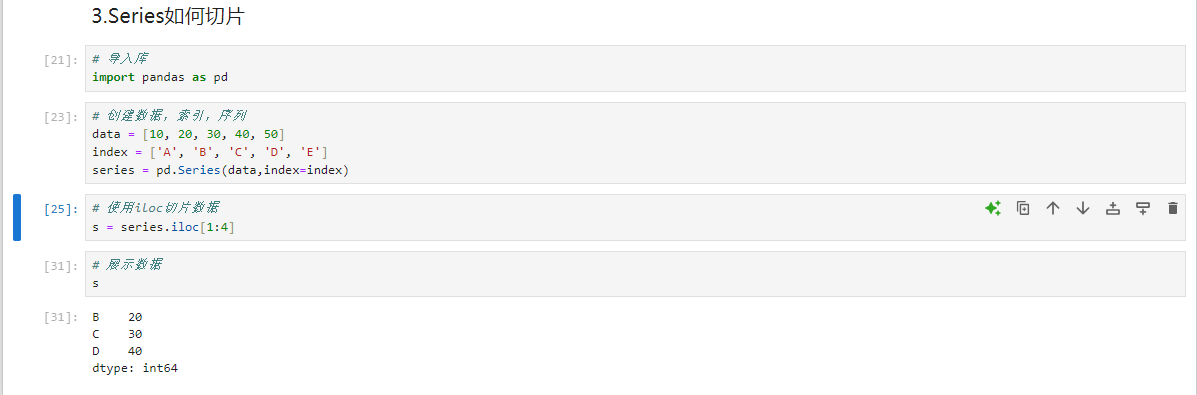
标签索引
位置索引切片(使用
loc):使用自定义索引标签来进行切片操作切片的范围包含起始标签和结束标签对应的元素
代码示例
python# 导入库 import pandas as pd # 创建数据,索引,序列 data = [10, 20, 30, 40, 50] index = ['A', 'B', 'C', 'D', 'E'] series = pd.Series(data,index=index) # 使用iloc切片数据 s = series.loc['A':'D'] # 展示数据 s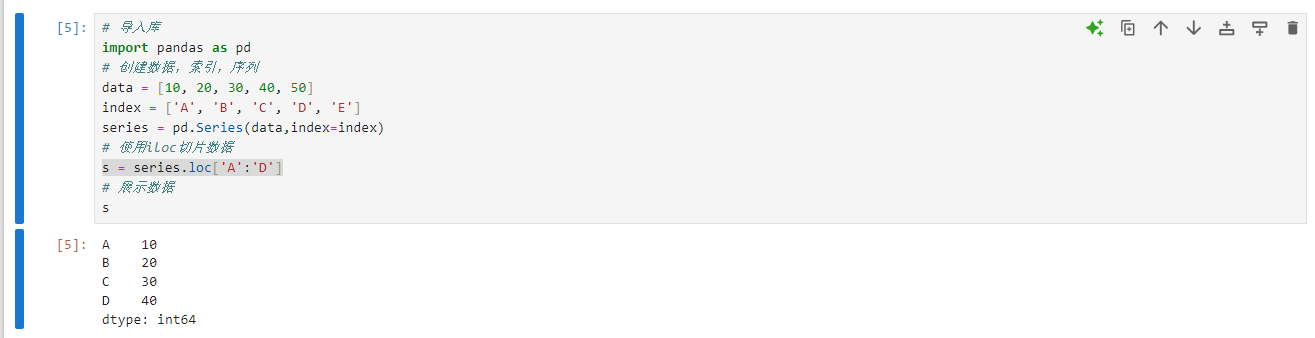
Series有那些属性?
在Pandas中,Series是一种一维数据结构,它有着许多的属性和方法。以下是一些常用的属性:
values:返回Series中的元素值组成的数组(Numpy数组)
pythonseries.valuesindex:返回Series的索引(标签)组成的数组
pythonseries.indexdtype:返回Series中数据的数据类型
pythonseries.dtypesize:返回Series中元素的个数(即Series的长度)
pythonseries.sizeshape:返回表示Series维度的元组,通常是(n,),其中n是Series中元素的个数
pythonseries.shapename:返回Series的名称
pythonseries.namendim:返回Series的纬度数,对于Series来说固定为1
pythonseries.ndim
这些属性可以用于快速查看和了解一个Series的结构,属性和元数据。例如,使用values属性获取Series中的数据值,使用index属性获取Series的索引,使用dtype属性查看数据的数据类型。在进行数据处理和分析时,这些属性通常用于检查数据的基本信息和描述性统计。
这里给出一份代码示例
# 导入库
import pandas as pd
# 创建数据,索引,序列
data = [10, 20, 30, 40, 50]
index = ['A', 'B', 'C', 'D', 'E']
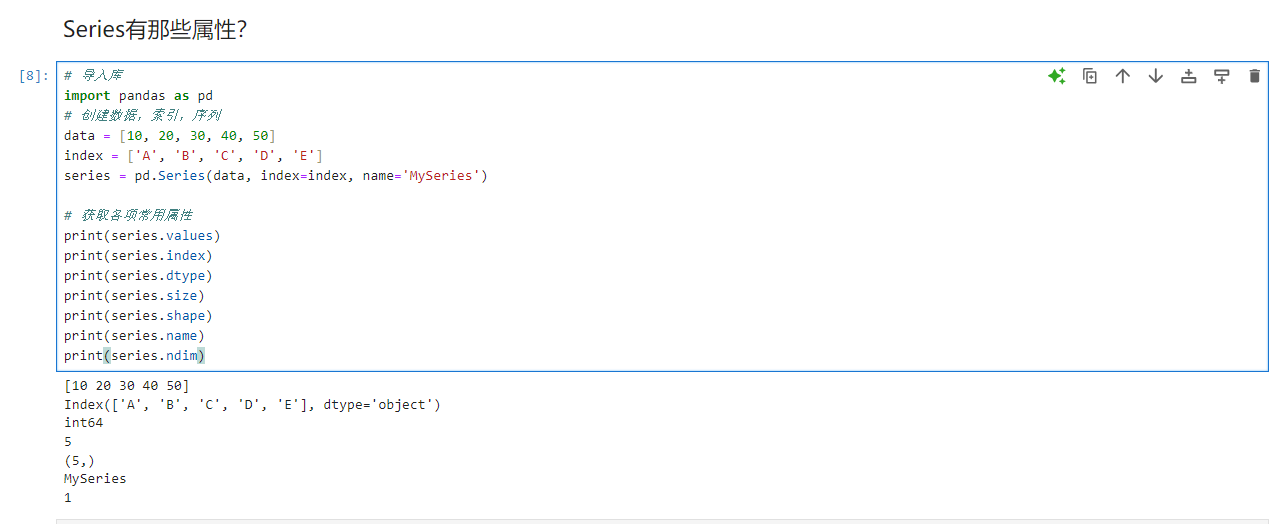
series = pd.Series(data, index=index, name='MySeries')
# 获取各项常用属性
print(series.values)
print(series.index)
print(series.dtype)
print(series.size)
print(series.shape)
print(series.name)
print(series.ndim)
Series是如何转变为DataFrame的?
DataFrame是Pandas中另一个重要的数据结构,在先前说了,DataFrame可以类比为是Excel表格,也就是说,DataFrame是一个二维表格,由行和列组成。
下面介绍两种将Series转变为DataFrame的方法:
使用pd.DataFrame()构造函数:
可以使用pd.DataFrame()构造函数将Series转换为DataFrame。在构造函数中,Series将作为一个列传递给DataFrame,并且可以通过指定列名来为DataFrame的列命名。
示例如下:
python# 导入库 import pandas as pd # 创建数据,索引,序列 data = [10, 20, 30, 40, 50] index = ['A', 'B', 'C', 'D', 'E'] series = pd.Series(data, index=index) # 将Series转换为DataFrame df = pd.DataFrame(series,columns=['Python']) df
使用Series.to_frame()方法:
Series对象提供了一个to_frame()方法,它可以将Series转换为DataFrame,该方法可以选择是否为DataFrame指定列名
代码示例:
python# 导入库 import pandas as pd # 创建数据,索引,序列 data = [10, 20, 30, 40, 50] index = ['A', 'B', 'C', 'D', 'E'] series = pd.Series(data, index=index) # 将Series转换为DataFrame df = series.to_frame(name='Python') df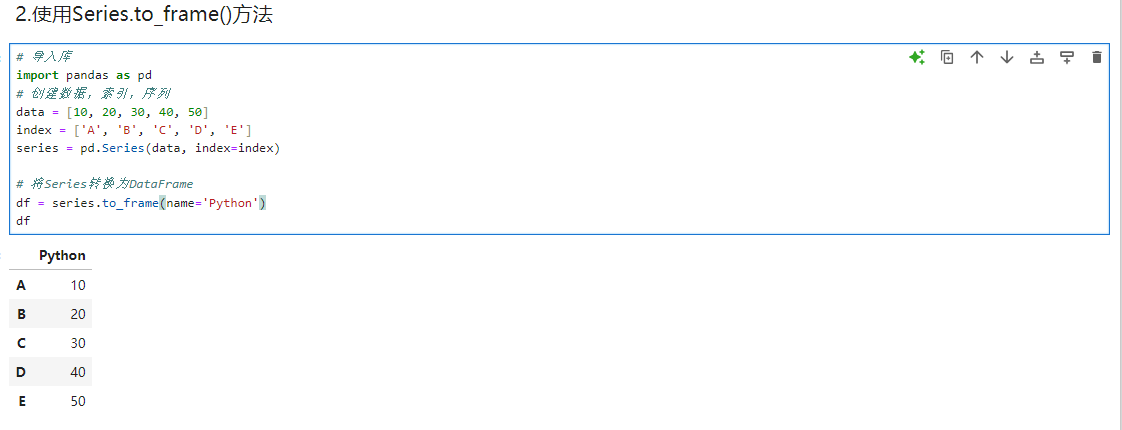
无论使用哪种方法,其结果都是将一个Series转换为一个只包含一个列的DataFrame。在DataFrame中,Series的索引将成为DataFrame的索引,并且列名将由你指定的名称决定,但如果你并未指定名称,将会使用Series的名称,如果Series在创建时没有指定名称,则会使用DataFrame默认的列名。
如何创建DataFrame?
先前我们已经介绍过了DataFrame,这里就不再做介绍了。在Pandas中,有很多的方法可以创建一个DataFrame,以下是常用的创建DataFrame的方法:
从字典创建DataFrame
可以使用Python的字典来创建DataFrame,其中字典的键将成为DataFrame的列名,而字典的值将成为DataFrame的列数据。
代码示例:
python# 导入库 import pandas as pd # 创建一个字典 data = { 'Name':['Alice', 'Bob', 'Charlie'], 'Age' :[25,30,35], 'City':['New York','London','Paris'] } # 从字典创建一个DataFrame df = pd.DataFrame(data) df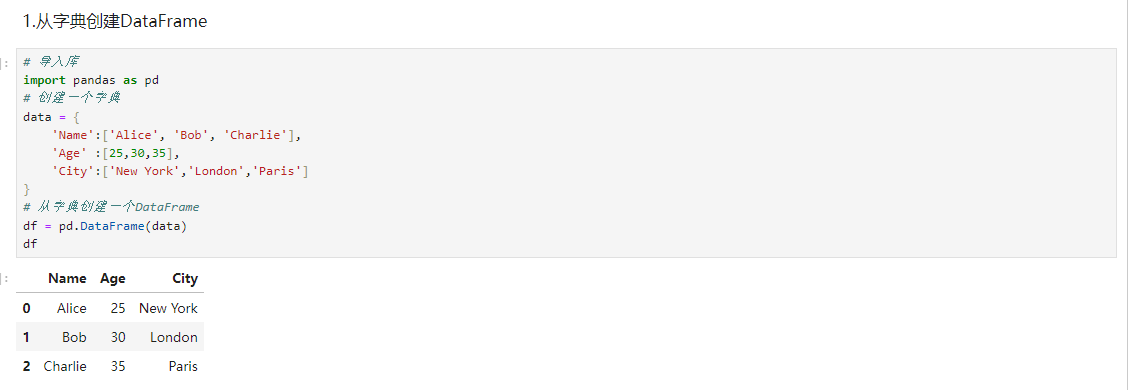
从列表嵌套元组或者列表的列表创建DataFrame
可以使用包含元组或者列表的列表来创建DataFrame,其中每个元组或列表表示一行数据
代码示例:
python# 导入库 import pandas as pd # 创建一个列表 data = [('Alice', 25, 'New York'), ('Bob', 30, 'London'), ('Charlie', 35, 'Paris')] df = pd.DataFrame(data, columns=['Name', 'Age', 'City']) df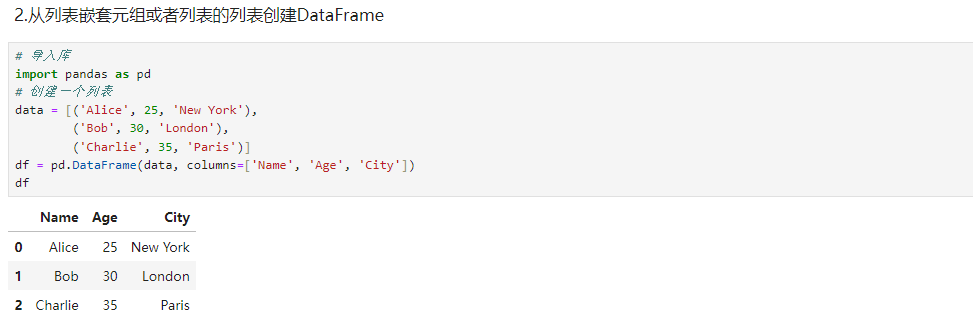
从Numpy数组创建DataFrame
可以使用Numpy数组来创建DataFrame
代码示例:
python# 导入库 import pandas as pd import numpy as np # 创建一个Numpy数组 data = np.array([ [10, 20, 30], [40, 50, 60], [70, 80, 90] ]) # 从Numpy数组创建DataFrame df = pd.DataFrame(data, columns=['A', 'B', 'C']) df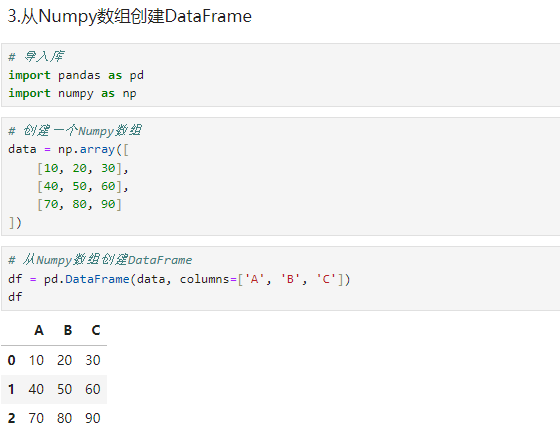
Pandas如何读写文件?
Pandas提供了各种方法来读取和写入不同的文件
写入文件
使用Pandas的to_开头的方法,可以将DataFrame数据写入到对应的文件中,常见的包括CSV,Excel,JSON,SQL数据库等。以下是一些代码示例
写入CSV文件:
python# 导入库 import pandas as pd import numpy as np # 创建一个 DataFrame df = pd.DataFrame(np.random.randint(1, 151, size=(100,3)), columns=['Python', 'Math', 'En']) # 将DataFrame写入到csv文件中 df.to_csv('output.csv',index=False) #index=False 表示不写入行索引写入Excel文件
python# 导入库 import pandas as pd import numpy as np # 创建一个 DataFrame df = pd.DataFrame(np.random.randint(1, 151, size=(100,3)), columns=['Python', 'Math', 'En']) # 将DataFrame写入到Excel文件中 df.to_excel('output.xlsx',index=False) #index=False 表示不写入行索引写入JSON文件
python# 导入库 import pandas as pd import numpy as np # 创建一个 DataFrame df = pd.DataFrame(np.random.randint(1, 151, size=(100,3)), columns=['Python', 'Math', 'En']) # 将DataFrame写入到JSON文件中 df.to_json('output.json',orient='split') #orient 参数表示方向性
读取文件
使用Pandas的read_开头的方法,可以将DataFrame数据写入到对应的文件中,常见的包括CSV,Excel,JSON,SQL数据库等。以下是一些代码示例
读取CSV文件
python# 读取根目录下名为output的csv文件,注意在jupyter中,会在cell中显示读取文件的内容 pd.read_csv('./output.csv')读取Excel文件
python# 读取根目录下名为output的Excel文件(后缀名是xlsx),注意在jupyter中,会在cell中显示读取文件的内容 pd.read_excel('./output.xlsx')读取JSON文件
python# 读取根目录下名为output的JSON文件,注意在jupyter中,会在cell中显示读取文件的内容 pd.read_json('./output.json',orient='split')
Pandas如何向Excel写入多个表单
要将多个DataFrame写入到同一个Excel文件中,需要使用Pandas中的ExcelWriter对象,ExcelWriter允许你将多个DataFrame写入到同一个Excel文件的不同sheet中。实现步骤如下
创建多个DataFrame
python# 导入库 import pandas as pd # 创建两个DataFrame data_1 = { 'Name':['Alice', 'Bob', 'Charlie'], 'Age' :[25,30,35], 'City':['New York', 'London', 'Paris'] } data_2 = { 'Product':['A', 'B', 'C'], 'Price' :[10,20,30], 'Quantity':[100, 200, 300] } df_1 = pd.DataFrame(data_1) df_2 = pd.DataFrame(data_2)创建一个ExcelWriter对象
python# 创建ExcelWriter对象 with pd.ExcelWriter('多表.xlsx',engine='openpyxl') as ew:Python中的
with语法:Python 的
with语法确实是一个非常强大和有用的特性,它通常与上下文管理器一起使用,能够确保代码块执行完毕后,资源能够被正确地释放或重置,即使在发生异常的情况下也是如此。这种语法被称为“上下文管理器”(context manager)。with语法的基本用法如下:pythonwith context_manager as variable: # 代码块 # 这里的代码可以访问variable,它是context_manager的返回值 # 无论这个代码块是否发生异常,退出with代码块时都会执行context_manager的清理操作这里的
context_manager可以是任何实现了__enter__()和__exit__()方法的对象。当进入with代码块时,会调用__enter__()方法,而退出with代码块时,无论是否发生异常,都会调用__exit__()方法。使用pd.to_excel方法将DataFrame写入到Excel对象的不同sheet中
python# 创建ExcelWriter对象 with pd.ExcelWriter('多表.xlsx',engine='openpyxl') as ew: #将每个 DataFrame写入到不同的sheet中 df_1.to_excel(ew,sheet_name='Sheet_1',index=False) df_2.to_excel(ew,sheet_name='Sheet_2',index=False)
DataFrame如何创建多层索引?
首先我们想知道的是,什么是多层索引?
在回答这个问题之前,我们要回顾一些基本概念:
- 轴:在Pandas中,DataFrame有两个轴,分别是索引(或者按习惯称为行)轴和列轴。多层索引通常用于行轴,但也可以用于列轴。
- 标签:索引的每一层都有一个标签,这些标签定义了索引的层次结构。
在Pandas中,多层索引(也称为多级索引或层次化索引)是一种数据组织方式,它允许你使用多个列或维度来索引DataFrame。这种索引方式类似于Excel中的多级表头,可以提供更丰富的数据结构和更灵活的数据访问方式。
创建多层索引的方法有哪些呢?
使用由元组组成的列表:
该方法为DataFrame的索引和列提供由元组组成的列表,代码示例如下
python# 创建数据 data = { ('张三', '期中'): [98, 88], ('张三', '期末'): [149, 136], ('李四', '期中'): [130, 117], ('李四', '期末'): [147, 100] } # 指定列名 column_names = ['Python', 'Math'] # 使用列表(data.values()) 来获取所有成绩数据,并用列名来创建DataFrame df = pd.DataFrame(list(data.values()), columns=column_names) # 将字典的键转换为多级索引 df.index = pd.MultiIndex.from_tuples(data.keys()) # 在cell中显示数据 df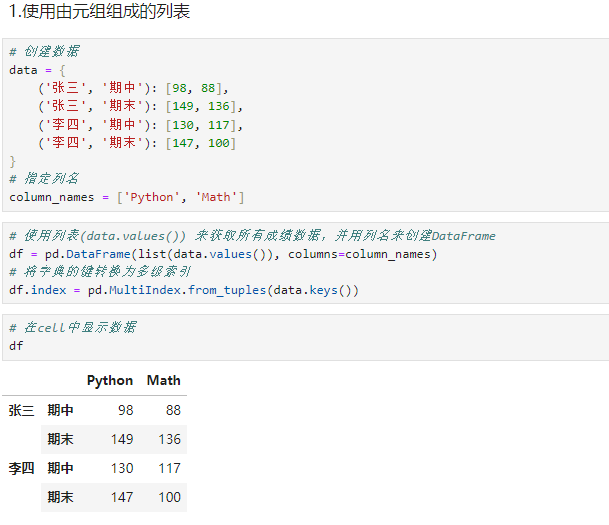
使用
pd.MultiIndex.from_tuples创建多层索引pd.MultiIndex.from_tuples是 Pandas 库中用于从元组列表创建多级索引(MultiIndex)的一个便捷方法。这个方法非常适合当你有一个由元组组成的列表,而你想要将这些元组用作 DataFrame 或 Series 的索引时。基本语法
pythonpd.MultiIndex.from_tuples(tuples, names=None)tuples:一个列表,其中每个元素是一个元组,元组中的元素数量决定了多级索引的级别数。names:一个可选参数,用于为每个索引级别指定名称。
代码示例
python# 创建一个元组列表作为多层索引的标签 index_labels = [('张三','期中'), ('张三','期末'), ('李四','期中'), ('李四','期末')] # 使用pd.MultiIndex.from_tuples创建多层索引 multi_index = pd.MultiIndex.from_tuples(index_labels, names=['Name','Exam']) # 创建数据 data = { 'Python' : [98,149,130,147], 'Math' : [88,136,117,100] } # 创建DataFrame df = pd.DataFrame(data,index=multi_index) # 展示数据 df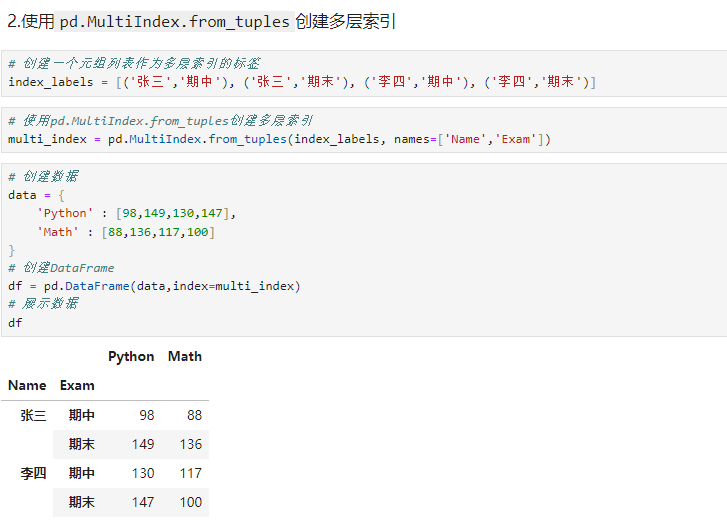
使用
pd.MultiIndex.from_arrays创建多层索引pd.MultiIndex.from_arrays是 Pandas 库中的一个函数,它允许你从多个数组创建一个多级索引(MultiIndex)。这个方法非常适合当你有多个数组,你想要将这些数组的元素组合成元组,并且用这些元组作为索引时。基本语法
pythonpd.MultiIndex.from_arrays(arrays, names=None)arrays:一个列表,其中每个元素是一个数组(或类似数组的对象),这些数组的元素将被组合成元组,形成多级索引的各个级别。names:一个可选参数,用于为每个索引级别指定名称。
代码示例
python# 创建一个多维数组作为多层索引的标签 index_labels = [['张三', '张三', '李四', '李四'], ['期中', '期中', '期末', '期末']] # 使用pd.MultiIndex.from_arrays创建多层索引 multi_index = pd.MultiIndex.from_arrays(index_labels, names=['Name','Exam']) # 创建数据 data = { 'Python' : [98,149,130,147], 'Math' : [88,136,117,100] } # 创建DataFrame df = pd.DataFrame(data,index=multi_index) # 展示数据 df
使用
pd.MultiIndex.from_product创建多层索引pd.MultiIndex.from_product是 Pandas 库中的一个函数,它用于从多个迭代器(如列表、数组等)的笛卡尔积创建一个多级索引(MultiIndex)。笛卡尔积意味着每个迭代器的第一个元素将与其它迭代器中的所有元素配对,然后是每个迭代器的第二个元素,依此类推。基本用法
pythonpd.MultiIndex.from_product(iterables, names=None)iterables:一个迭代器的列表,每个迭代器包含一个索引级别的所有可能值。names:一个可选参数,用于为每个索引级别指定名称。
代码示例
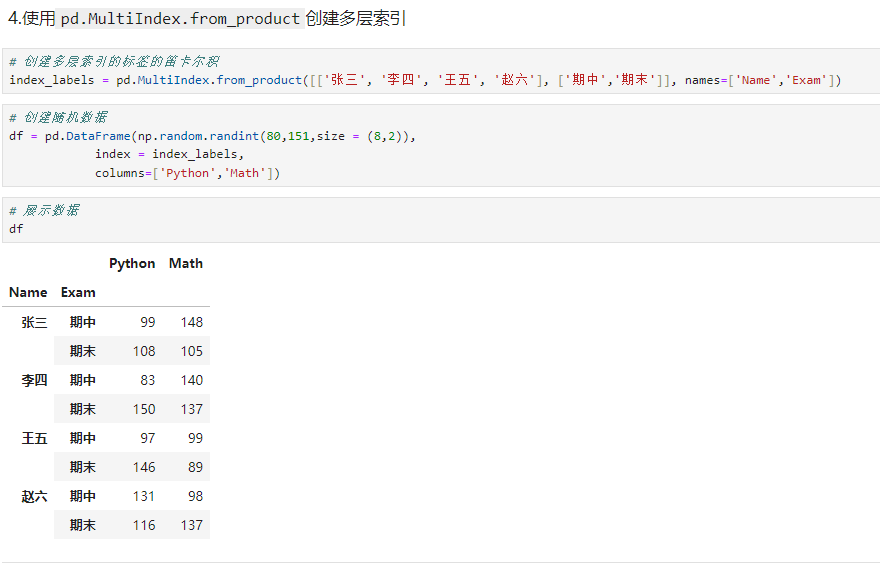
python# 创建多层索引的标签的笛卡尔积 index_labels = pd.MultiIndex.from_product([['张三', '李四', '王五', '赵六'], ['期中','期末']], names=['Name','Exam']) # 创建随机数据填充DataFrame df = pd.DataFrame(np.random.randint(80,151,size = (8,2)), index = index_labels, columns=['Python','Math']) # 展示数据 df