Working with External Libraries
在本教程中,你将学习Python中的imports(导入),获取一些使用不熟悉的库(以及它们返回的对象)的技巧,并深入研究operator overloading(运算符重载)。
Imports
到目前为止,我们已经讨论了语言内置的类型和函数。
但Python最大的好处之一(尤其是对于数据科学家而言)是有大量高质量的自定义库为它编写。
其中一些库位于“标准库”中,这意味着你可以在运行Python的任何地方找到它们。可以轻松添加其他库,即使它们并不总是与Python一起提供。
无论哪种方式,我们都将通过**imports(导入)**来访问这段代码。
我们将从从标准库导入math开始我们的例子。
import math
print("It's math! It has type {}".format(type(math)))
It's math! It has type <class 'module'>
math是一个module(模块)。模块只是其他人定义的变量的集合(你也可以称之为命名空间)。我们可以使用内置函数dir()查看数学中的所有名称。
print(dir(math))
['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
可以使用点语法访问这些变量。其中一些指向简单值,如 math.pi
print("pi to 4 significant digits = {:.4}".format(math.pi))
pi to 4 significant digits = 3.142
但在这个模块中,我们能找到的大多是函数,比如math.log:
math.log(32, 2)
5.0
当然,如果我们不知道math.log做了什么,可以对它调用help():
help(math.log)
Help on built-in function log in module math:
log(...)
log(x, [base=math.e])
Return the logarithm of x to the given base.
If the base not specified, returns the natural logarithm (base e) of x.
我们也可以在模块本身上调用help()。这将为我们提供模块中所有函数和值的组合文档(以及模块的高级描述)。
help(math)
sorry 有点长我懒得写,你自己开个jupyer看看吧~
Other import syntax
如果我们知道将经常在math中使用函数,可以使用更短的别名导入它,以节省输入时间(尽管在本例中“math”已经很短了)。
import math as mt
mt.pi
3.141592653589793
您可能已经看到过使用某些流行的库(如Pandas、Numpy、Tensorflow或Matplotlib)实现此功能的代码。例如,通常
import numpy as npandimport pandas as pd.
as只是重命名导入的模块。它等价于这样做:
import math
mt = math
如果我们可以自己引用math模块中的所有变量,不是很好吗? 例如,如果我们可以只引用pi而不是math.pi=或者mt.pi?好消息是:我们可以做到。
from math import *
print(pi, log(32, 2))
3.141592653589793 5.0
Import * 使你可以直接访问模块中的所有变量(无需任何虚线前缀)。
坏消息:一些纯粹主义者可能会抱怨你这么做。
更糟糕的是:他们有点道理。
from math import *
from numpy import *
print(pi, log(32, 2))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/tmp/ipykernel_19/3018510453.py in <module>
1 from math import *
2 from numpy import *
----> 3 print(pi, log(32, 2))
TypeError: return arrays must be of ArrayType
发生了什么事?它以前明明好好的!
这种“star imports(from module import *)”偶尔会导致奇怪、难以调试的情况。
这里的问题在于math和numpy模块都有log函数,但它们具有不同的语义。因为我们第二次从numpy导入了log函数,所以它的log会覆盖(或“投影”)我们从math中导入的log变量。
一个比较好的折中方案是只从每个模块中导入我们需要的特定内容:
from math import log, pi
from numpy import asarray
Submodules
我们已经看到,模块包含可以引用函数或值的变量。需要注意的是,它们也可以有变量引用其他模块。
import numpy
print("numpy.random is a", type(numpy.random))
print("it contains names such as...",
dir(numpy.random)[-15:]
)
numpy.random is a <class 'module'>
it contains names such as... ['seed', 'set_state', 'shuffle', 'standard_cauchy', 'standard_exponential', 'standard_gamma', 'standard_normal', 'standard_t', 'test', 'triangular', 'uniform', 'vonmises', 'wald', 'weibull', 'zipf']
因此,如果我们像上面那样导入numpy,那么调用random “submodule” 中的函数将需要两个点。
# Roll 10 dice
rolls = numpy.random.randint(low=1, high=6, size=10)
rolls
array([3, 4, 3, 4, 5, 5, 2, 1, 3, 3])
Oh the places you’ll go, oh the objects you’ll see
因此,在上了6节课之后,你就可以熟练使用整型、浮点型、布尔型、列表、字符串和字典(对吧?)
即使这是真的,事情也不会就此结束。当你使用各种库来完成特定任务时,你会发现它们定义了自己的类型,你必须学会使用这些类型。例如,如果你使用图形库matplotlib,你将接触到它定义的表示子图、图形、标记和注释的对象。pandas函数将提供数据框和序列。
在这一节中,我想与你分享一个使用奇怪类型的快速生存指南。
Three tools for understanding strange objects
在上面的单元格中,我们看到调用numpy函数会得到一个“array”。我们以前从未见过这样的东西(至少不是在本课程中)。但不要惊慌:我们有三个熟悉的内置函数来帮助我们。
1: type() (what is this thing?)
type(rolls)
numpy.ndarray
2: dir() (what can I do with it?)
print(dir(rolls))
['T', '__abs__', '__add__', '__and__', '__array__', '__array_finalize__', '__array_function__', '__array_interface__', '__array_prepare__', '__array_priority__', '__array_struct__', '__array_ufunc__', '__array_wrap__', '__bool__', '__class__', '__complex__', '__contains__', '__copy__', '__deepcopy__', '__delattr__', '__delitem__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__iand__', '__ifloordiv__', '__ilshift__', '__imatmul__', '__imod__', '__imul__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__ior__', '__ipow__', '__irshift__', '__isub__', '__iter__', '__itruediv__', '__ixor__', '__le__', '__len__', '__lshift__', '__lt__', '__matmul__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmatmul__', '__rmod__', '__rmul__', '__ror__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__setitem__', '__setstate__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__xor__', 'all', 'any', 'argmax', 'argmin', 'argpartition', 'argsort', 'astype', 'base', 'byteswap', 'choose', 'clip', 'compress', 'conj', 'conjugate', 'copy', 'ctypes', 'cumprod', 'cumsum', 'data', 'diagonal', 'dot', 'dtype', 'dump', 'dumps', 'fill', 'flags', 'flat', 'flatten', 'getfield', 'imag', 'item', 'itemset', 'itemsize', 'max', 'mean', 'min', 'nbytes', 'ndim', 'newbyteorder', 'nonzero', 'partition', 'prod', 'ptp', 'put', 'ravel', 'real', 'repeat', 'reshape', 'resize', 'round', 'searchsorted', 'setfield', 'setflags', 'shape', 'size', 'sort', 'squeeze', 'std', 'strides', 'sum', 'swapaxes', 'take', 'tobytes', 'tofile', 'tolist', 'tostring', 'trace', 'transpose', 'var', 'view']
# If I want the average roll, the "mean" method looks promising...
rolls.mean()
3.3
# Or maybe I just want to turn the array into a list, in which case I can use "tolist"
rolls.tolist()
[3, 4, 3, 4, 5, 5, 2, 1, 3, 3]
3: help() (tell me more)
# That "ravel" attribute sounds interesting. I'm a big classical music fan.
help(rolls.ravel)
Help on built-in function ravel:
ravel(...) method of numpy.ndarray instance
a.ravel([order])
Return a flattened array.
Refer to `numpy.ravel` for full documentation.
See Also
--------
numpy.ravel : equivalent function
ndarray.flat : a flat iterator on the array.
# Okay, just tell me everything there is to know about numpy.ndarray
# (Click the "output" button to see the novel-length output)
help(rolls)
太长了不愿意复制粘贴了。。。
Operator overloading
下面表达式的值是什么?
[3, 4, 1, 2, 2, 1] + 10
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/tmp/ipykernel_19/2144087748.py in <module>
----> 1 [3, 4, 1, 2, 2, 1] + 10
TypeError: can only concatenate list (not "int") to list
多傻的问题。当然这是一个错误。
但是……
rolls + 10
array([13, 14, 13, 14, 15, 15, 12, 11, 13, 13])
我们可能会认为,Python严格规定了其核心语法的行为方式,例如+、<、in、==或用于索引和切片的方括号。但事实上,它采取了一种不干涉的方式。定义新类型时,可以选择它的加法运算方式,或者该类型的对象等于其他值意味着什么。
列表的设计者认为,不允许将列表与数字相加。numpy数组的设计者则采取了不同的方式(为数组的每个元素添加数字)。
下面是numpy数组如何与Python操作符进行意外交互的几个例子(至少与列表不同)。
# At which indices are the dice less than or equal to 3?
rolls <= 3
array([ True, False, True, False, False, False, True, True, True,
True])
xlist = [[1,2,3],[2,4,6],]
# Create a 2-dimensional array
x = numpy.asarray(xlist)
print("xlist = {}\nx =\n{}".format(xlist, x))
xlist = [[1, 2, 3], [2, 4, 6]]
x =
[[1 2 3]
[2 4 6]]
# Get the last element of the second row of our numpy array
x[1,-1]
6
# Get the last element of the second sublist of our nested list?
xlist[1,-1]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/tmp/ipykernel_19/3020169379.py in <module>
1 # Get the last element of the second sublist of our nested list?
----> 2 xlist[1,-1]
TypeError: list indices must be integers or slices, not tuple
Numpy的ndarray类型专门用于处理多维数据,因此它定义了自己的索引逻辑,允许我们通过元组来指定每个维度的索引。
When does 1 + 1 not equal 2?
还有比这更奇怪的事情。你可能听说过(甚至使用过)tensorflow,这是一个广泛用于深度学习的Python库。它大量使用运算符重载。
import tensorflow as tf
# Create two constants, each with value 1
a = tf.constant(1)
b = tf.constant(1)
# Add them together to get...
a + b
<tf.Tensor: shape=(), dtype=int32, numpy=2>
A + b不是2,而是(引用tensorflow文档)……
一个操作输出的符号句柄。它并不保存该操作输出的值,而是提供了一种在TensorFlow tf.Session中计算这些值的方法。
重要的是要意识到这样一个事实:这种事情是可能的,而且库经常会以一种不明显或看似神奇的方式使用运算符重载。
理解Python操作符应用于整型、字符串和列表时的工作原理,并不能保证您能够立即理解它们应用于tensorflow张量、numpy ndarray或pandas DataFrame时的工作原理。
例如,一旦你对DataFrames有了一点了解,下面这样的表达式就开始看起来很直观:
python# Get the rows with population over 1m in South America df[(df['population'] > 10**6) & (df['continent'] == 'South America')]
但是它为什么会起作用呢?上面的例子提供了5个不同的重载操作符。这些操作的作用是什么?当事情开始出错时,它可以帮助你知道答案。
Curious how it all works?
你是否曾经在一个对象上调用过help()或dir(),并想知道这些带有双下划线的名称到底是什么?
print(dir(list))
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
事实证明,这与运算符重载直接相关。
当Python程序员想要定义操作符对其类型的行为时,他们通过实现以2个下划线开头和结尾的特殊名称的方法来实现,例如__lt__、setattr__或__contains。通常,遵循这种双下划线格式的名称对Python有特殊的含义。
例如,[1,2,3]中的表达式x实际上在幕后调用了列表方法__contains__。它等价于(丑陋得多的那个)[1,2,3].contains(x)。
如果你想了解更多,可以查看Python的官方文档,其中描述了很多很多这种特殊的“下划线”方法。
我们不会在这几节课中定义我们自己的类型(如果有时间的话!),但我希望你能在以后的道路上体验到定义自己的奇妙、怪异类型的乐趣。
Exercise:
Question 1
在完成列表和元组的练习后,Jimmy注意到,根据他的estimate_average_slot_payout函数,Learn Python赌场的老虎机实际上是被操纵的,从长远来看是有利可图的。
从口袋里的200美元开始,吉米已经玩了500次老虎机,每次旋转后都将他的新余额记录在一个列表中。他使用Python的matplotlib库绘制了平衡随时间变化的图表:
# Import the jimmy_slots submodule
from learntools.python import jimmy_slots
# Call the get_graph() function to get Jimmy's graph
graph = jimmy_slots.get_graph()
graph
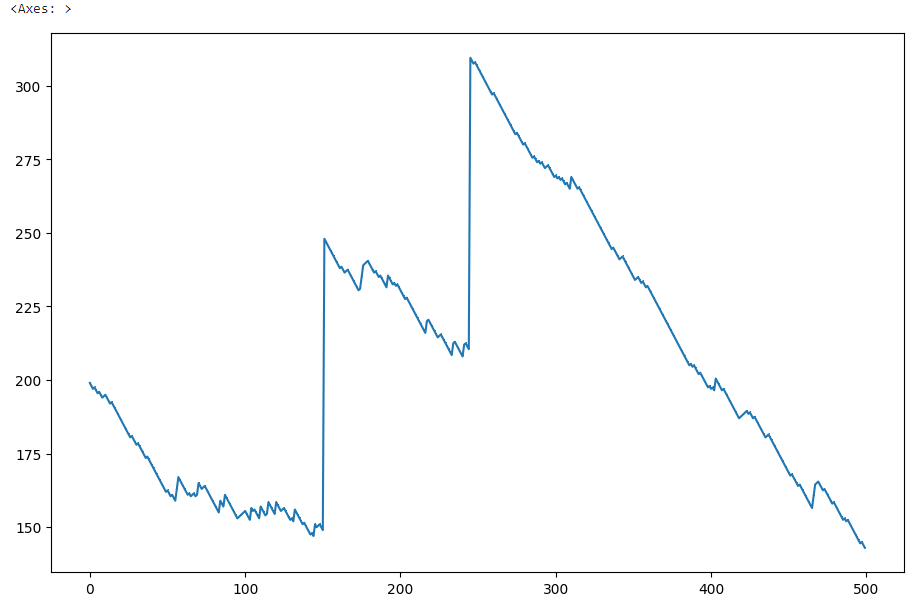
如你所见,他最近运气不太好。他想在推特上加上一些精选的表情符号,但就目前来看,他的粉丝可能会感到困惑。他问你是否可以帮他做以下修改:
- 添加标题“抽500次老虎机的结果”。
- 让y轴从0开始。
- 在y轴上添加标签“Balance”
调用type(graph)后,可以看到Jimmy绘制的图形的类型是matplotlib.axis._subplots.axessubplot。嗯,这是一个新的类型。通过调用dir(graph),你会发现三个看起来很有用的方法:.set_title()、。set_ylim()和。set_ylabel()。
根据Jimmy的要求,使用这些方法完成函数prettify_graph。我们已经帮你完成了第一个请求(设置标题)。
(记住:如果你不知道这些方法的作用,请使用help()函数!)
def prettify_graph(graph):
"""Modify the given graph according to Jimmy's requests: add a title, make the y-axis
start at 0, label the y-axis. (And, if you're feeling ambitious, format the tick marks
as dollar amounts using the "$" symbol.)
"""
graph.set_title("Results of 500 slot machine pulls")
graph.set_ylim(bottom=0)
graph.set_ylabel("Balance")
# Complete steps 2 and 3 here
graph = jimmy_slots.get_graph()
prettify_graph(graph)
graph
Question 2
这是一个非常具有挑战性的问题。别忘了你可以得到提示!
Luigi正在尝试进行分析,以确定在马里奥赛车赛道上赢得比赛的最佳道具。他有一些字典列表形式的数据,如下所示:
[ {‘name’: ‘Peach’, ‘items’: [‘green shell’, ‘banana’, ‘green shell’,], ‘finish’: 3}, {‘name’: ‘Bowser’, ‘items’: [‘green shell’,], ‘finish’: 1},
# Sometimes the racer’s name wasn’t recorded
{‘name’: None, ‘items’: [‘mushroom’,], ‘finish’: 2}, {‘name’: ‘Toad’, ‘items’: [‘green shell’, ‘mushroom’], ‘finish’: 1}, ]
“items”是赛车手在比赛中获得的所有能量道具列表,“finish”是他们在比赛中的位置(1代表第一名,3代表第三名,以此类推)。
他编写了下面的函数,接收这样一个列表,并返回一个字典,将每个元素映射为获得第一名的次数。
def best_items(racers):
"""Given a list of racer dictionaries, return a dictionary mapping items to the number
of times those items were picked up by racers who finished in first place.
"""
winner_item_counts = {}
for i in range(len(racers)):
# The i'th racer dictionary
racer = racers[i]
# We're only interested in racers who finished in first
if racer['finish'] == 1:
for i in racer['items']:
# Add one to the count for this item (adding it to the dict if necessary)
if i not in winner_item_counts:
winner_item_counts[i] = 0
winner_item_counts[i] += 1
# Data quality issues :/ Print a warning about racers with no name set. We'll take care of it later.
if racer['name'] is None:
print("WARNING: Encountered racer with unknown name on iteration {}/{} (racer = {})".format(
i+1, len(racers), racer['name'])
)
return winner_item_counts
他在上面的一个小示例列表上进行了尝试,似乎正常工作了:
sample = [
{'name': 'Peach', 'items': ['green shell', 'banana', 'green shell',], 'finish': 3},
{'name': 'Bowser', 'items': ['green shell',], 'finish': 1},
{'name': None, 'items': ['mushroom',], 'finish': 2},
{'name': 'Toad', 'items': ['green shell', 'mushroom'], 'finish': 1},
]
best_items(sample)
然而,当他尝试在他的完整数据集上运行它时,程序崩溃并报出TypeError。
你能猜到为什么吗?试着运行下面的代码单元格,看看Luigi得到的错误消息。一旦你确定了bug,在下面的单元格中修复它(这样它就可以正常运行了)。
提示:Luigi的bug类似于我们在教程中讨论star导入时遇到的bug。
Error Code:
# Import luigi's full dataset of race data
from learntools.python.luigi_analysis import full_dataset
# Fix me!
def best_items(racers):
winner_item_counts = {}
for i in range(len(racers)):
# The i'th racer dictionary
racer = racers[i]
# We're only interested in racers who finished in first
if racer['finish'] == 1:
for i in racer['items']:
# Add one to the count for this item (adding it to the dict if necessary)
if i not in winner_item_counts:
winner_item_counts[i] = 0
winner_item_counts[i] += 1
# Data quality issues :/ Print a warning about racers with no name set. We'll take care of it later.
if racer['name'] is None:
print("WARNING: Encountered racer with unknown name on iteration {}/{} (racer = {})".format(
i+1, len(racers), racer['name'])
)
return winner_item_counts
# Try analyzing the imported full dataset
best_items(full_dataset)
Corrotr Code:
# Import luigi's full dataset of race data
from learntools.python.luigi_analysis import full_dataset
# Fix me!
def best_items(racers):
winner_item_counts = {}
for i in range(len(racers)):
# The i'th racer dictionary
racer = racers[i]
# We're only interested in racers who finished in first
if racer['finish'] == 1:
for j in racer['items']:
# Add one to the count for this item (adding it to the dict if necessary)
if j not in winner_item_counts:
winner_item_counts[i] = 0
winner_item_counts[i] += 1
# Data quality issues :/ Print a warning about racers with no name set. We'll take care of it later.
if racer['name'] is None:
print("WARNING: Encountered racer with unknown name on iteration {}/{} (racer = {})".format(
i+1, len(racers), racer['name'])
)
return winner_item_counts
# Try analyzing the imported full dataset
best_items(full_dataset)
Question 3
假设我们想创建一个新类型来表示blackjack中的手牌。我们可能想对这种类型做的一件事是重载比较操作符,如>和<=,以便我们可以使用它们来检查一只手是否打败另一只手。如果我们可以这样做,那就太酷了:
python>>> hand1 = BlackjackHand(['K', 'A']) >>> hand2 = BlackjackHand(['7', '10', 'A']) >>> hand1 > hand2 True
好吧,我们不会在这个问题中做所有这些(定义自定义类有点超出了这些课程的范围),但是我们要求您在下面的函数中编写的代码与我们定义自己的BlackjackHand类时必须编写的代码非常相似。(我们把它放在__gt__魔术方法中,为>定义我们的自定义行为 >。)
根据文档字符串填充blackjack_hand_greater_than函数的函数体。
def hand_total(hand):
"""Helper function to calculate the total points of a blackjack hand.
"""
total = 0
# Count the number of aces and deal with how to apply them at the end.
aces = 0
for card in hand:
if card in ['J', 'Q', 'K']:
total += 10
elif card == 'A':
aces += 1
else:
# Convert number cards (e.g. '7') to ints
total += int(card)
# At this point, total is the sum of this hand's cards *not counting aces*.
# Add aces, counting them as 1 for now. This is the smallest total we can make from this hand
total += aces
# "Upgrade" aces from 1 to 11 as long as it helps us get closer to 21
# without busting
while total + 10 <= 21 and aces > 0:
# Upgrade an ace from 1 to 11
total += 10
aces -= 1
return total
def blackjack_hand_greater_than(hand_1, hand_2):
total_1 = hand_total(hand_1)
total_2 = hand_total(hand_2)
return total_1 <= 21 and (total_1 > total_2 or total_2 > 21)